
- Tämä juttu on arkistoitua sisältöä, joka tarjotaan luettavaksi sellaisenaan. Tämän vuoksi siinä voi olla saavutettavuusongelmia.
Kysymyksillä on yhä paikkansa
Myös ison datan aikakaudella tarvitaan lomaketutkimuksia. Tietolähteet ovat toisiaan täydentäviä, eivät poissulkevia. Tiedon alkuperä ja tuotantovaiheet on kuitenkin aina tunnettava, ettei niiden pohjalta synny virheellisiä tulkintoja ja johtopäätöksiä.
Tilastoitavat ilmiöt ja tietotarpeet ovat ison datan tulosta huolimatta monesti sellaisia, että tiedot on kerättävä kysymällä eivätkä tarjolla olevat hallinnolliset aineistot tai iso data pysty niitä korvaamaan.
Tilaston ja lomaketutkimukseen perustuvan tutkimuksen, surveyn, mieli on relevantin tiedon tuottamisessa. Samat tavoitteet pätevät myös isoon dataan, joten tiedon käyttäjän on tärkeä osata jäsentää käyttämänsä tiedon lähteitä ja ymmärtää sen alkuperää.
Yrityksiä koskevasta lomaketutkimuksesta on hiljattain julkaistu ensimmäinen kansainvälinen laaja käsikirja (Snjikers ym. 2013, kts. juttu alla.). Nostamme siitä esiin erityisesti tiedon laatuun liittyviä kysymyksiä sekä tiedonkeruuvälineiden suunnitteluun liittyvää menetelmiä.
Lomakkeesta tuli yhteiskuntatieteiden mittausväline
”Mittaa se mikä on mitattavissa, tee mitattavaksi se, mitä ei voi mitata”. Näillä Galileo Galilein sanoilla Tuukka Perhoniemi kuvaa väitöskirjassaan Mitan muunnelmat (2014) mittaamisen muuttumista luonnontieteen menetelmäksi, jossa havainnot ja matematiikka yhdistyivät. 1800-luvulle tultaessa syntyi uudenlainen malli objektiiviselle tiedolle, kun tilastollisuutta, sattumaa ja vaihtelua, ryhdyttiin pitämään yhtä merkittävinä kuin luonnonlakeja.
Myös suomalainen tilastotoimi kumpuaa tästä mittaamisen historiallisesta perinteestä. Ensimmäiset taloustilastot syntyivät hallinnollisten rekisterien pohjalta, kuten vuodesta 1813 julkaistu Tullihallituksen ulkomaankauppatilasto. Hallinnollisten aineistojen riittämätön tietosisältö ja otantatutkimuksen keksiminen toivat kuitenkin 1900-luvulla kyselylomakkeen tilastolliseen tiedonhankintaan yhteiskuntatieteiden mittausinstrumentiksi, ja kummatkin toimivat edelleen tilastojen tietopohjana.
Kyselylomake on lomaketutkimuksessa se väline, jolla asioita tehdään mitattavaksi. Tilastojen takana ovat teoria yhteiskunnan toiminnasta ja käsitteet, joilla yhteiskuntaa kuvataan. Käsitteet ovat abstrakteja, ja operationalisoinnin kautta niille määritellään konkreettisia ja empiirisesti havaittavia vastineita. Esimerkiksi käsite ”työtön” voidaan operationalisoida henkilöksi, joka etsii työtä aktiivisesti ja joka voi aloittaa työn kahden viikon sisällä.
Luonnontieteissä olion tai lauman käyttäytymistä voitaisiin tarkkailla havaintojen keräämiseksi. Mutta kun kyseessä on ihminen tai ihmisyhteisö kuten yritys, suullinen tai kirjallinen kommunikaatio itse tutkittavan kohteen kanssa on käytännöllisempää ja eettisempää. Havainnot saadaan siis operationalisoinnista johdettujen kysymysten kautta kysymällä.
Kyselylomakkeesta puhumme, kun nämä kysymykset esitetään vastaajalle paperilla tai näytöllä tai haastattelija esittää ne joko puhelimessa tai kasvotusten. Vastaaja saa tehtäväksi lomakkeelle vastaamisen ja tietojen palauttamisen tilaston tekijälle tämän määrittelemässä muodossa. Se, kuinka vastaaja tässä tehtävässä onnistuu, vaikuttaa keskeisesti prosessin lopputuotteen, tilaston laatuun.
Kyselytutkimus onnistuu, kun operationalisoinnin käänteistoimenpiteen eli tulkinnan avulla pystytään aineiston kautta, tässä tapauksessa lomakevastauksista, tarkastelemaan tosielämän säännönmukaisuutta ja teorian paikkansapitävyyttä (Sund 2015).
Ruohonjuuritason teoreetikot
Lomaketestauksessa on kyse tilastontekijöiden jalkautumisesta vastaajien luokse koettelemaan kyselylomakkeen sisältöä ja käytettävyyttä. Keskeisinä syinä toiminnalle ovat olleet havainnot siitä, että vastaaminen tilastoviranomaisen lähettämiin kyselyihin ei olekaan niin helppoa kuin on oletettu.
Tällä taas on suora vaikutus tilastoissa ilmenevään mittausvirheeseen ja yrityksiin kohdistuvaan vastausrasitteeseen, joiden minimoiminen on yksi keskeinen virallisen tilastotoimen tavoite myös kansainvälisesti. Toisaalta tiedonkeruuseen liittyvät vaikeudet ovat tilastontekijän näkökulmasta ylimääräinen kustannus, joka syntyy tietojen editoinnista sekä ylimääräisistä yhteydenotoista yrityksiin.
Antiikissa theoria tarkoitti kiinnostuneen ihmisen pidättyväistä tarkkailua siitä, miten asiat ovat; teoreetikko ei puuttunut asioiden kulkuun, mutta oli osa havaintotilannetta (Perhoniemi 2014). Samassa hengessä menemme lomaketestauksissa yrityksiin ja pyrimme saamaan näkyviin asioiden kulun ja vastaajan ajatukset samalla, kun vastaaja täyttää tiedonkeruulomaketta. Sähköisten tiedonkeruuvälineiden toimivuus on keskeinen kiinnostuksen kohde.
Suurimpana poikkeamana normaaliin vastaamistilanteeseen on se, että pyydämme vastaajaa kertomaan samanaikaisesti, kuinka hän päätyy vastauksiinsa tai mitä mahdollisia ongelmia itse vastaamiseen tai tietojen kokoamiseen vastattavaan muotoon liittyy.
Tiedonkeruulomakkeen käytettävyyden rinnalla myös lomakkeen sisältökysymykset ovat kiinnostuksen kohteena. Yrityskyselyjen kohdalla itse kuvauskohteen, yritysten liiketoimintaympäristön, muutos aiheuttaa haasteita perinteisille kyselyille. Haluttu tieto voi olla pirstaloitunut yrityksen sisällä jopa maailman eri puolille, tai sen tuottaminen vastauslomakkeelle voi osoittautua, jos ei mahdottomaksi, niin ainakin työlääksi tehtäväksi.
Yhteiskunnan ja ilmiöiden muuttuessa yhä nopeammin, myös kieli ja tavat jäsentää asioita muuttuvat. Tämä tarkoittaa, että kysymyksillä tietoja keräävän tahon tulee entistä paremmin ymmärtää vastaajia ja niitä olosuhteita, missä vastaukset syntyvät.
Kun asioista ”tehdään mitattavia” eli ne käsitteellistetään mitattavaksi sopivalla tavalla, korostetaan aina jotakin ominaisuutta toisten kustannuksella (Perhoniemi 2014). Tämä on näkynyt yrityksille suunnatuissa kyselyissä esimerkiksi siinä, että useat muotoilut lomakkeella sopivat paremmin teollisuusyrityksiin kuin palvelualan yrityksiin. Tällä on luonnolliset historialliset taustansa niin tilastotoimessa kuin yhteiskunnassakin, joka oli toimialarakenteeltaan hyvin erilainen silloin kun ensimmäisiä yritystiedonkeruulomakkeita suunniteltiin.
Toisaalta tilastotoimen luonteeseen taas kuuluu vakaus ja sen myötä hitaus muutoksissa, koska ilmiöitä halutaan tarkastella ja vertailla kymmenien tai joskus jopa satojen vuosien taakse. Tämä koskee niin luokituksia kuin tiedonkeruulomakkeitakin, jotka ovat keskeisiä tietojen vertailukelpoisuuden ja aikasarjojen kannalta. Keskeiset kansainväliset luokituspäivitykset esimerkiksi toimialan ja ammatin osalta tapahtuvat usein yli 10 vuoden välein.
Vastaustilanteen ja tiedon laadun yhteys
Iso data syntyy pääsääntöisesti automatisoituina verkkohakuina (web scraping) tai oheistuotteena kuten verkkopalvelun käyttäjien lokitietoina. Tiedonkeruun kohde ei välttämättä tiedä tai jatkuvasti tiedosta, että sen toiminnasta kerätään tietoa.
Yritystilastoinnissa kuitenkin tarvitaan nimenomaan tietoja, joihin vain tilastoinnin kohteena olevalla yrityksellä on pääsy ja myös tiukka intressi säännellä, kenelle tietoja luovutetaan. Tiedonkerääjään on tällöin ymmärrettävä yritysten sisäistä raportointia ja tietojärjestelmiä sekä sitä, mitä tietopyyntöön vastaaminen yritykseltä vaatii.
Snjikers ym. (2013) kuvaavat käsikirjassaan yksityiskohtaisesti tilastoviranomaisen ja vastauksen antavan yrityksen välistä vuorovaikutusta. Kirjoittajien mukaan vastaamisprosessiin, josta itse lomakkeen täyttäminen on vain yksi osa, liittyy erilaisia tehtäviä ja rooleja:
1. Tiedon lähteen kartoitus; mitä tietoa yrityksestä on saatavilla niiden omista rekistereistä ja mihin vastaaja voi vastata muistinvaraisesti
2. Vastaamistehtävän organisointi; kuka yrityksen puolesta vastaa ja kuinka monta vastaajaa tarvitaan ja millä aikataululla
3. Kysymysten ymmärtäminen ja tulkinta
4. Muistaminen ja tietojen hakeminen
5. Vastauksen sopivuuden arviointi
6. Vastauksen kommunikointi
7. Tietojen tarkistus ja luovutus sekä mahdolliset yrityksen sisäiset järjestelyt luovutettavien tietojen tarkistamiseksi sekä päätökset siitä, mitä tietoja yritys haluaa luovuttaa
Yritykset raportoivat liiketoiminnastaan lähtökohtaisesti kahdella eri tavalla. Yrityksen johto tarvitsee tietoa liiketoiminnan johtamisen ja ohjaamisen tueksi, jotta tavoitteeseen toiminnan kannattavuudesta päästäisiin. Lainsäädäntö myös asettaa velvoitteitta kuten tilinpäätöksen tekemisen ja raportit verotusta varten.
Kyselytutkimuksiin osallistuminen taas tarkoittaa yritykselle sellaisten tietojen raportoimista, mitä ei yrityksissä tehdä lähtökohtaisesti. Vaikka pääosa tilastoviranomaisten tekemistä kyselyistä on lakisääteisiä, yritys ei aina ole varautunut kyselyissä esiintyvien tietojen raportointiin, vaikka yrityksiä tästä ennakkoon informoidaankin. Tämä taas johtaa vastaamistilanteessa erilaisiin haasteisiin.
Vastaajat joutuvat usein pohtimaan sitä, kuinka toimivat tilanteissa, joissa tieto ei ole helposti saatavilla. Tilaston laadun kannalta tällä on taas suuri merkitys. Yhteydet tietojen saatavuuden ja vastausten laadun välillä nousevat tavalla tai toisella esiin yrityslomakkeisiin vastaamisessa ja näkyvät lukuisissa testaustilanteissamme. Bavdaž (2010) on mallintanut tätä yhteyttä kuvion 1 mukaisesti.
Kuvio 1. Tietojen saatavuuden ja vastauksen laadun välinen yhteys
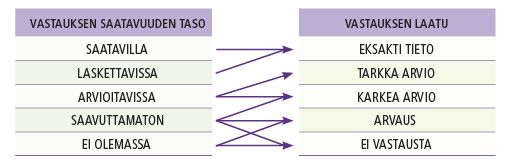
Lähde: Bavdaž 2010
Kenellä on sisällön määrittelyvalta?
Kuinka voisi jäsentää isoa dataa ja lomaketutkimusaineistoja niin, että tilaston käyttäjät ymmärtäisivät niiden keskeiset eroavaisuudet – ja siten myös niiden käytön reunaehtoja? Minkälaisesta tiedosta isossa datassa on kysymys?
Kuten Hannes Heikinheimo ja Antti Ukkonen (2015) toteavat, ison datan tarkoituksena ei lähtökohtaisesti ole ollut tutkia ja ymmärtää lukujen taustalla olevia ilmiöitä vaan toteuttaa ennustavia ja ennakoivia verkkopalveluita. Ison datan soveltamisessa uranuurtajia ovat erityisesti olleet internetyhtiö Google tiedonhakupalveluillaan ja sosiaalisen median palvelut, kuten Facebook, käyttäjälle kohdennetuilla sisällöillään.
Nerokas oivallus on ollut siinä, että valtavissa massa-aineistoissa yksinkertaiset korrelaatiot muuttujien välillä toimivat ennustamisessa paremmin kuin muuttujien syy–seuraus-suhteiden ymmärtäminen ja näiden pohjalta rakennetut monimutkaiset laskentamallit. Aineistoa ja sen yksittäisiä havaintoja ei tarvitse tuntea, kun olennaista on käyttäjälle välittyvä kokemus verkkopalvelun älykkyydestä, eli vaikkapa kuinka hyvin sen onnistuu valikoida kuluttajalleen räätälöityjä hakutuloksia tai ystävien tuottamaa sosiaalisen median sisältöä.
Isoa dataa ja sen työkaluja ei siis ole luotu mittareiksi ja mittausvälineiksi, vaikka siihenkin ne taipuvat. Tilastoissa, ja etenkin lomaketutkimuksissa, asia on juuri päinvastoin. Tilasto on objektiivinen ja puolueeton yhteiskunnallisen ilmiön kvantitatiivinen kuvaus.
Tilastojen kuvaamat faktat toimivat yhteiskunnallisen päätöksenteon pohjana, mutta iso data algoritmeineen tekee myös itse päätöksiä käyttäjänsä puolesta.
Robert Groves (2011) puhuu lomaketutkimuksen ja ison datan luonteista käsitteillä suunniteltu (designed) data ja orgaaninen (organic) data. Suunniteltuun dataan liittyy aina joku tunnistettava toimija. Kuinka toimija suunnittelun toteuttaa, riippuu tekijästä, mutta toimijalla on joka tapauksessa valta tehdä haluamiaan ratkaisuja tiedonkeruuseen ja kysymyksenasetteluun liittyen.
Tätä valtaa taas kolmannella osapuolella, kuten tilastoviranomaisella, ei ole isoon dataan liittyen, ja hallinnollistenkin aineistojen osalta vain rajallisesti. Esimerkiksi lainsäädäntöön tehtävät muutokset voivat lopettaa tilastojen tekoon sopivan hallinnollisen aineiston tuottamisen.
Tilastojen tekemisen näkökulmasta eri aineistoja voidaan vertailla sisällön määrittelyvallan kautta. Tällä tarkoitamme sitä, missä määrin tilaston tekijä voi määritellä minkälaiseen sisältöön ja aineistoon tilastot perustuvat. Tätä havainnollistaa kaksiulotteinen kuvio 2, jossa toisena ulottuvuutena on havaintojen ja mittausulottuvuuksien määrä, ja jolla iso data on ylivertainen.
Kuvio 2. Sisällön määrittelyvallan ja aineiston koon yhteys
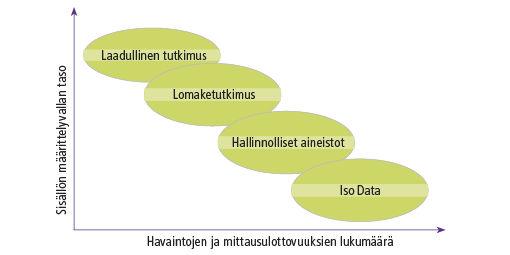
Hallinnollisissa aineistoissa sisällön määrittelyvalta on kullakin asianomaisella viranomaisella. Esimerkiksi Väestörekisterikeskuksen väestötietojärjestelmässä on perustiedot Suomen kansalaisista ja Suomessa vakinaisesti asuvista ulkomaalaisista.
Sisällön määrittelyvaltaa voidaan tilastojen näkökulmasta käyttää näiden hallinnollisten aineistojen suunnittelussa tilastojen tarpeet huomioiden. Lainsäädännöllä on luonnollisesti keskeinen rooli ja asia on huomioitu uudessa tilastolaissa. Tärkeätä on myös muistaa, että moni hallinnollinen aineisto itsessään kerätään kysymyksillä ja lomakkeilla eli lomaketutkimuksen työkaluilla.
Lomaketutkimuksessa taas tiedon kerääjä on aktiivinen toimija ja kykenee määrittämään, miten ja millä välineillä kysymykset vastaajille esitetään. Tiedon kerääjän ja suunnittelijan etäisyys tiedon ”loppukäyttäjään” on myös läheisempi, kun voidaan suoraan esittää haluttu kysymys.
Laadullinen tutkimus on toinen ääripää; esimerkiksi kouralliseen havaintoja perustuvissa haastatteluissa kysyttyjä asioita kyetään myös tarkentamaan suoraan vastaajilta ja saamaan vielä yksityiskohtaisempaa tietoa kuin mitä lomaketutkimuksen strukturoiduilla lomakkeilla kyetään keräämään.
Iso data ja lomaketutkimus tulevat varmasti molemmat olemaan tulevaisuudessa keskeisiä yhteiskuntaa kuvaavia tietolähteitä. Lomaketutkimusalan keskeinen järjestö AAPOR (2015) onkin julkaissut hiljattain raportin, jossa kuvataan isoa dataa laajalti ja pohditaan sen käyttöä lomaketutkimuksessa. Raportissa järjestö suosittelee:
-kehittämään standardeja ison datan läpinäkyvään käyttöön lomaketutkimuksessa
-näkemään molemmat tietolähteet toisiaan täydentävinä, ei poissulkevina
-ryhtymään kouluttamaan organisaatioita ison datan käytössä
-informoimaan kansalaisia ison dataan hyödyistä ja riskeistä
-selventämään käytettyä terminologiaa
-olemaan aktiivinen toimija julkishallinnon puolella ison datan käytön infrastruktuurin kehittämisessä lomaketutkimuksessa
On data pientä tai isoa, tekstiä tai numeroita, tiedonkäyttäjän tulee olla kriittinen tietolähteiden osalta. Tärkeää on ymmärtää tiedon ja aineiston syntyprosessin alkuvaiheet. Ja jo ennen sitä on hyvä tietää, kuinka tietotarpeet ja tutkimuskysymykset on määritelty. Onko ne tehty käytettävissä olevan aineiston perusteella jälkikäteen, vai päinvastoin.
Kirjoittajat työskentelevät Tilastokeskuksen tiedonhankinta -yksikön SurveyLaboratoriossa.
Lähteet:
AAPOR Report on Big Data 2015. American Association for Public Opinion research. AAPOR Big Data Task Force.
http://doku.iab.de/grauepap/2015/BigDataTaskForceReport_FINAL_2_12_15.pdf.
Bavdaž, Mojka 2010. The Multidimensional Integral Business Survey Response Model. Survey Methodology 36.
Groves, R. 2011. “Designed Data” and “Organic Data”. The Director’s Blog, The U.S. Census Bureau, 31.5.2011.
Heikinheimo, Hannes & Ukkonen Antti 2015. Ison datan alkulähteillä. Tieto&trendit – talous- ja hyvinvointikatsaus 2/2015.
Perhoniemi, Tuukka 2014. Mitan muunnelmat – miten määritämme maailmaa, ihmistä ja tietoa. Helsinki: Vastapaino.
Snijkers, Ger & Haraldsen, Gustaf & Jones, Jacqui & Willimack, Diana 2013. Designing and conducting business surveys. Hoboken, New Jersey: John Wiley & Sons.
Sund, Reijo 2015. Miksi isoon dataan hukutaan? Tieto&trendit – talous- ja hyvinvointikatsaus 2/2015.

Ensimmäinen käsikirja yrityskyselyistä
Designing and Conducting Business Surveys (2013) on laatuaan ensimmäinen yrityskyselyjä koskeva käsikirja, jonka ohjaavana näkökulmana on prosessilaatu. Tietopohjan muodostavat useat eri oppiaineet, kuten laskentatoimi, sosiologia, sosiaalipsykologia, psykologia, organisaatiotiede ja lomaketutkimusmetodologia.
Käsikirja muodostaa kattavan kokonaiskuvan yrityskyselyjen suunnittelusta ja toteutuksesta aina tilastojen ja tutkimusten raportointiin asti. Se on suunnattu yrityskyselyjen parissa toimiville sekä yrityskyselyjen tuloksien ja niistä tehtävien tilastojen käyttäjille.
Kirja tarjoaa tutkimustietoon ja esimerkkeihin perustuvia suosituksia mittausvirheiden, kustannusten ja vastausrasitteen hallitsemiseksi. Se avaa myös useita uusia alueita tulevaisuuden tutkimukselle.